
Easy Tech #26 - 5 concepts techniques que tout PM devrait maîtriser
Ils vont changer ta manière de voir la tech

Salut à toi,
J’espère que tu vas bien 😃
(petite innovation, pas de photo aujourd’hui… j’espère que ça vous plaira 😂)
Aujourd’hui, on revient sur des sujets techniques important à maîtriser en tant que profil product au sein d’une équipe produit ou d’une organisation.
Avec au menu :
→ le Domain-Driven Design
→ L’inversion de dépendance
→ Le découplage
→ Le Test-Driven Development
→ L’intégration continue
Mini annonce
C’est la première fois que j’en parle en public. Je suis parti de L’Oréal il y a quelques semaines. Et je me lance dans l’aventure entrepreneuriale, autour du Product.
Voici ce que je fais :
→ J’aide des start-ups sur leurs enjeux strat et produit en tant que CPO part time.
→ J’aide de plus grosses structures, PME à grands groupes, sur leurs enjeux pour maximiser l’efficacité de leurs produits et de leurs outils digitaux.
→ Je vais ouvrir une ligne (payante) pour 45 minutes d’échange avec moi sur des sujets Product / Stratégie / LinkedIn… ou autres ! Tu peux me dire ici si ça t’intéresse.
→ Je donne de la visibilité aux entreprises et aux initiatives de tout type, via le sponsoring de cette newsletter.
Si un de ces sujets t’intéresse, tu peux me contacter directement en répondant à cet email.
Domain driven Design
Qu’est-ce que c’est ?
Le Domain-Driven Design désigne une approche pour faire échanger les différents membres d’une organisation pour améliorer la gestion des sujets métier lorsqu’on développe des logiciels.
De manière triviale on pourrait dire que ça vise à “réconcilier le métier et la tech”.

Le constat de base des grands théoriciens du DDD est que la complexité de construire un logiciel vient de deux aspects : 1️⃣ la complexité de la technique ; 2️⃣ la complexité du métier.
Ils ont pour objectif d’améliorer la gestion du 2️⃣ par différentes pratiques. En effet, il y a pas mal de marges d’amélioration à ce niveau :
→ Les connaissances métier sont localisées chez certains experts, mais peu documentées et très silottées
→ Les problèmes métiers à résoudre sont complexes avec des subtilités non détectables par des publics non avertis
→ Il y a parfois trop de déconnexion entre le métier -pas intéressé par la tech- et les techs -pas intéressés par le métier
La mise en place d’échange et la création d’un langage commun entre les acteurs métier et les acteurs tech va permettre de surmonter ces problèmes.
Les deux grandes références sur le sujet sont :
Le livre Domain-Driven Design : tackling complexity in the heart of software d’Eric Evans qui a posé les bases de cette théorie mais qui est très difficile à lire
Le livre Implementing Domain-Driven Design de Vaughn Vernon qui est plus accessible mais reste difficile quand on n’a pas l’habitude de lire du code
En quoi ça consiste ?
Comme on l’a dit, on va mettre en place des activités pour faire discuter l’ensemble des acteurs.
Derrière cela va nous permettre de :
→ Construire une même langue (“ubiquitous language”) pour tous les échanges entre acteurs techniques et métiers. Il y a toujours des interprétations différentes entre les termes employés par les équipes de dév et les équipes métier. Chacun finit par avoir ses habitudes et utilise des mots qui font sens pour lui. Faire juste parler tout le monde permet de réduire le risque d’écarts et d’incompréhension.
→ Découper l'environnement métier en zones / contextes (“bounded contexts”). Cela part de l’idée que tout produit répond à un enjeu métier / business. Et cet enjeu métier va pouvoir se séparer en différentes zones et contextes. On va définir ces zones pour qu’elles soient autonomes les unes par rapport aux autres. Par exemple, si je travaille dans l’environnement métier e-commerce, il y aurait une zone autour de 1️⃣ la logistique et les opérations ; 2️⃣ le paiement et la facturation ; 3️⃣ la gestion du catalogue de produits…
→ Utiliser les discussions entre les acteurs pour construire des scénarios d'usage de l'application. Les discussions ne vont pas rester purement théoriques ou sémantiques “comment tu appelles xxx ? Nous on l’appelle yyy”. Non, on va rentrer dans le concret et mobiliser ce langage commun afin de définir les grandes approches pour utiliser notre produit. On co-construit des scénarios qui constituent des très bons candidats pour les user stories du développement.
→ Faire brainstormer tous les acteurs pour illustrer les relations entre les zones / contextes qui composent l'environnement métier. Une fois qu’on a identifié les grands contextes métier, on s’intéresse à comment ils interagissent.
Pourquoi est-ce pertinent ?
Le DDD va nous permettre de générer plusieurs bénéfices :
→ Moins de quiproquos entre développeurs et utilisateurs. Comme évoqué plus haut : développeur et acteur métier n’ont pas les mêmes termes d’où le risque de quiproquos. Par exemple quand je bossais pour le Ministère de l’Intérieur, on parlait de “Dossier d’infraction”. Seulement la notion de dossier n’avait pas forcément la même signification pour le développeur que pour le Ministère de la Justice ou que pour les Policiers / Gendarmes… pas facile de se comprendre et donc risque que les fonctionnalités ne soient pas parfaitement adaptées.
→ Une meilleure connaissance métier et technique. L’avantage de faire discuter tout le monde et de construire ce langage commun, c’est qu’on va pouvoir décrire de manière précise le fonctionnement de ce sur quoi on bosse. L’univers “métier” va être cartographié sous forme de scénario pour expliciter les détails sous-jacents. C’est important car souvent, les projets échouent non pas à cause de la maîtrise technique. Mais plutôt parce qu’on ne sait pas mettre les bons mots sur le problème métier qu’on essaye de régler. Et comme on ne sait pas bien le décrire, on ne le comprend pas bien non plus. Donc on n’arrive pas à le résoudre.
→ Une meilleure dynamique d'équipe. c’est basique et simple mais mine de rien, tout le monde est content de se parler. Tu t’embrouilles plus difficilement avec quelqu’un que tu vois toutes les deux semaines en réunion. Faire travailler ensemble TOUS les acteurs permet d'engager tout le monde dans la démarche. Tout le monde est dans le même bateau. C’est notamment important pour les développeurs. On leur fait parfois sentir qu’ils ne seraient pas de bonne compagnie pour les utilisateurs finaux ou les métiers. En plus d’être désagréable pour eux, c’est démotivant. Donc il ne faut pas hésiter à les valoriser et à leur permettre de voir ces utilisateurs.
Inversion de dépendance
Qu’est-ce que c’est ?
On l’a vu plus haut pour le DDD et on l’a également déjà évoqué dans l’édition sur l’architecture, un des enjeux d’une conception technique de haut niveau, c’est de réussir à avoir des composants isolés et autonomes les uns par rapport aux autres.
Par exemple, si j’ai un site web e-commerce, je vais essayer que les composants :
Page d’accueil
Catalogue
Page produit
Paiement
Soient relativement isolés et autonomes. Notamment pour éviter que si page d’accueil a un problème, ce problème se diffuse et contamine d’autres composants.
On comprend bien comment cela se matérialise au niveau macro et fonctionnel. L’exemple du site e-commerce le montre bien.
En revanche, au niveau technique, c’est parfois plus compliqué à matérialiser. C’est à ça que va servir l’inversion de dépendance.
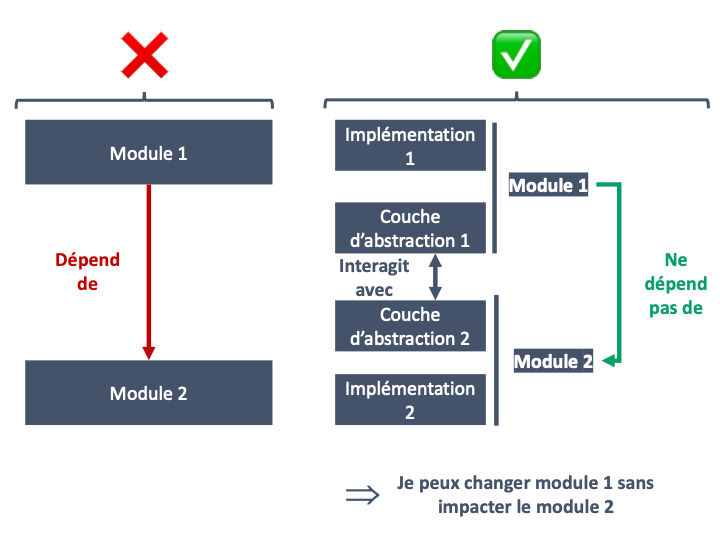
L’idée va être de mettre en place des couches d’abstraction (comme des APIs) entre les modules afin de pouvoir centraliser à ce niveau, les interactions entre les modules. Cela permet d’éviter d’emmêler les modules et d’introduire des liens / dépendances entre eux. L’implémentation reste cachée, protégée bien au chaud.
En quoi ça consiste ?
Il s’agit d’un concept très technique avec lequel le PM aura peu d’interactions dans la vie du produit. En revanche, de manière indirecte, le PM contribuera à avoir une inversion de dépendance qui protège les bons éléments. Quelques pistes pour aller dans ce sens :
→ Assurer un dialogue nourri entre les développeurs et le métier, très tôt, et tout au long du travail de création du produit (par exemple en suivant les approches DDD). Cela va permettre de clarifier les règles métier les plus sensibles et importantes. Les développeurs sauront donc qu’il faut les protéger en priorité.
→ Valider avec les développeur que les règles métier sont bien protégées des détails d’implémentation technique. Ce n’est pas un point à forcément évoquer au jour le jour. En revanche c’est important d’en discuter de temps en temps. Par exemple, si on crée dans notre application une connexion avec une nouvelle base de donnée, la règle métier et le choix de la technologie de la base données doivent être indépendants.
→ Pousser pour des approches API-first. Il s’agit d’essayer de créer un produit et ses différents modules en se demandant comment les informations transmises par chaque module vont être consommés. Typiquement, pour les modules précédents : page d’accueil, catalogue ou page produit. La question prioritaire n’est pas “comment je vais développer l’intérieur de la page d’accueil ou de la page produit”. La question est plutôt de savoir à quoi vont servir les informations remontées par la page produit. De la sorte, je me focalise sur ce qui a vraiment de la valeur, les éléments métier les plus importants. Que je vais ensuite pouvoir protéger des détails d’implémentation qui eux, le sont moins.
Pour quel bénéfice ?
Tout simplement pour protéger les règles métier business, des évolutions techniques au niveau de l’implémentation.
Si on prend l’exemple d’une application bancaire très simple qui analyse un dossier et dit si ce dossier peut recevoir un crédit ou non. Il y a donc deux modules dans l’application :
→ Un module analyse qui dit s’il faut donner le crédit ou non
→ Un module stockage, qui contient une base de données pour stocker le dossier et renvoyer les informations sur le dossier lorsque le module analyse en a besoin.
Qu’est-ce qui est important ? Ce sont les règles métier, à savoir les règles au sein du module analyse qui nous disent dans quelles conditions le crédit peut être accordé ou non.
Inversement, est-ce que la manière dont le dossier est stocké est important ? Que ça soit une base NoSQL ou une base SQL ? Que ça soit telle version d’un logiciel ou une autre ? Tant que le dossier est stocké, ça n’est pas grave. C’est un détail.
En conséquence, l’inversion de dépendance s’appliquerait dans cette situation en s’assurant que le module analyse ne dépend pas du module stockage. Donc :
⇒ On peut changer les règles de calcul du module analyse facilement si nécessaire, sans devoir se poser des questions sur les potentiels impacts que cela aurait sur la base de données.
Découplage
Qu’est-ce que c’est ?
On est sur un concept plus général que l’inversion de dépendance mais qui n’est pas non plus une méthode ou une discipline à proprement parler comme le DDD.
Le découplage renvoie à une caractéristique des logiciels qu’on construit. Ces logiciels sont composés de différents modules. Et on veut que ces modules soient faiblement couplés ou découplés. Cela renvoie au fait que chaque module ou composant est indépendant des autres. Ils ne sont pas imbriqués ou emmêlés comme le présente le schéma ci-dessous :
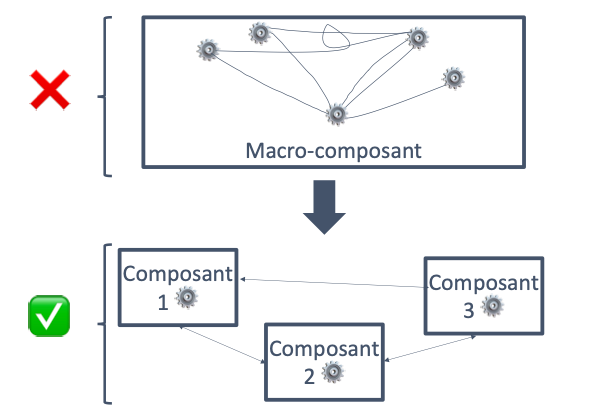
Un peu de la même manière qu’on range ses affaires en séparant les tee-shirts, les pulls, les pantalons et les sous-vêtements…
On va essayer également de ne pas mélanger les composants et de regrouper des éléments ensemble lorsque cela fait sens et que c’est cohérent.
Une question que vous vous posez peut-être est la suivante : quelle est la “taille” du composant à partir duquel je dois le découpler des autres ? Difficile de donner une réponse toute faite. On vise de manière générale à découper les grandes fonctions métier, les grandes tâches réalisées par les applications. Dans le cas de mon exemple ecommerce, de telles fonctions seraient page d’accueil, catalogue etc… Parfois on essaye également d’avoir un découplage à un niveau plus petit : au sein de ces modules. En revanche il ne faut pas être trop maximaliste. À un moment trop de découplage devient contre-productif. Pour reprendre l’exemple des vêtements : on a un tiroir pour les tee-shirts mais on n’a pas 15 tiroirs pour ranger les différents tee-shirts (1 pour les tee-shirts blancs, 1 pour les XS, 1 pour les S, 1 pour les bleus etc…)
Pas de livre ou de référence vraiment dédiée au “découplage” mais c’est un objectif général qui est très important. On en a notamment parlé avec Pierre Criulanscy lors d’un webinaire il y a quelques mois.
En quoi ça consiste ?
Pareil ici, on est sur un sujet sur lequel le PM aura un impact indirect. Toutefois c’est intéressant de se demander en quoi cela pourrait se matérialiser :
→ Regrouper les composants par proximité métier. Le découplage est toujours une conséquence de l’architecture fonctionnelle. Car l’agencement fonctionnel (ou métier) des choses vient avant leur agencement technique. Et avant de se demander quelle technologie on utilise, on se demande le besoin auquel ça répond. Or un Product Manager a la connaissance de cette architecture fonctionnelle. C’est à dire, le processus par lequel son utilisateur réalise les actions pour lesquelles le produit a été développé.
→ Regrouper les composants en fonction de leur rythme de déploiement. C’est une autre manière intelligente de regrouper. Certains éléments de l’application ne vont potentiellement pas beaucoup évoluer. C’est pertinent de les regrouper afin de garder à d’autres endroits les composants qui évoluent beaucoup plus souvent. Ne serait-ce que parce que les développeurs auront moins vocation à travailler régulièrement sur les composants qui évoluent peu. Pas besoin de leur encombrer l’esprit avec. En tant que Product Manager, on a une bonne visibilité sur les modules qui vont être les plus demandeurs en termes d’évolutivité. Et inversement, ceux qui seront moins exigeants.
Pourquoi est-ce pertinent ?
De manière générale, je pense qu’on peut à peu près assimiler le fait de construire une application bien architecturée avec le fait que cette application présentent des modules découplés. Plus largement, voici pourquoi le découplage est pertinent :
→ Des changements ou bugs plus isolés. Avec une architecture emmêlée, c'est dur de bouger un truc à un endroit... sans que ça ait des effets de bord à un autre endroit. À l’inverse, c’est bien plus simple avec une archi bien découpée. Cela vaut pour des fonctionnalités mais aussi pour les correctifs d’éventuels bugs. On trouvera plus facilement la cause d’un bug et sa correction sera plus indolore.
→ C’est plus simple à gérer pour les équipes. En ne mélangeant pas tout, la cohérence globale est meilleure. Le rangement est plus efficace. De même que si tu demandes à quelqu’un de ranger tes vêtements ou de chercher quelque chose dans ton armoire, ça sera plus facile si c’est bien rangé que si ça ne l’est pas. Pour l’onboarding de nouvelles ressources, le découplage permet donc un grand gain de temps.
→ Une meilleure évolutivité à long terme. Au final c’est la continuité de cette isolation des changements ou des bugs. En ayant des modules bien découplés, je vais pouvoir facilement faire grossir chaque module historique (si ça devient trop gros, je redécouple à l’intérieur) ou rajouter d’autres modules (ils seront bien isolés et indépendants des modules historiques). Attention, c’est ce qui rend possible le passage à l’échelle et c’est inversement ce qui le rend impossible si on n’a pas fait attention à ça.
Test-Driven Development
Qu’est-ce que c’est ?
Lorsqu’on écrit du code en général, le processus est le suivant :
→ Je réfléchis à ce que je veux faire
→ Je le découpe en macro-tâches
→ J’écris des lignes pour réaliser une première macro-tâche
→ Je teste cette première macro-tâche
→ Si ça marche, je passe à la seconde macro-tâche
etc…
Je ne suis pas expert mais c’est comme ça que je faisais lorsque je créais des macro Excel ou des scripts Python. Et c’est comme ça que me l’ont présenté des développeurs.
Le problème dans ce processus, c’est que lorsqu’on a bien avancé sur la fonctionnalité, sur la macro-tâche, on a souvent la flemme de faire la partie test.
→ À la fois parce que c’est une partie un peu démoralisante, en gros très souvent ça ne marche pas et il faut que je modifie ce que je viens de finir
→ À la fois parce qu’on se dit que ça ne vaut pas la peine de le faire macro-tâche par macro-tâche, on se dit qu’on n’a qu’à attendre d’avoir fait toutes les macro-tâches !
Du coup, on risque de ne pas tester suffisamment les lignes de code écrites avec deux conséquences :
→ Soit je mettrais beaucoup plus de temps à valider les fonctionnalités finalisées.
→ Soit la fonctionnalité finalisée ne posera pas de problème quand je la vérifierai… mais elle en posera lorsqu’elle sera déployée en production par exemple (et donc l’utilisateur ne sera pas content.)
L’idée du TDD, c’est d’éviter ça justement ! On va écrire petit à petit le code des applications… en commençant toujours par des tests automatiques avant d’écrire la moindre ligne de code.
→ Un petit test
→ Un petit peu de code
→ On valide que ça marche
→ Puis on repart
→ Un petit test
→ Un petit peu de code
…
C’est ce qui est présenté dans le cycle ci-dessous :

On va détailler un petit peu plus, notamment la partie refacto.
Mais voici l’esprit général du TDD.
Si ça vous intéresse de creuser, je vous conseille de suivre Michael Azerhad pour progresser sur le sujet. Il a notemment fait cette vidéo sur le sujet.
En quoi ça consiste ?
Rentrons un peu dans le détail. Encore une fois - j’ai l’impression de me répéter 😅 - ça ne concerne évidemment pas le PM… qui n’est jamais amené à écrire des lignes de code. Toutefois je trouve que l’approche est belle et intéressante.
Imaginons que je développe une fonction pour additionner deux nombres : a et b. Si je dis à la fonction que a = 0 et que b =1 ; alors la fonction me répondra que a+b=0+1= 1.
Pour rédiger le code correspondant à cette fonction, on va enchaîner les cycles comprenant trois principales phases :
Situation initiale : il n’y a pas de code, rien d’écrit.
→ Je commence par écrire un test qui échoue ; ce test va typiquement vérifier si la fonction me renvoie bien 1 lorsque je lui envoie 0 et 1 pour a et b. Or, évidemment le test ne sera pas concluant à ce stade ! Il n’y a pas de code, rien d’écrit à part le test. Le test va donc être rouge ❌
→ J’écris ensuite la quantité minimale de code pour que le test passe au vert. ⚠️ il faut vraiment qu’il y ait très très peu de code. L’idée n’est pas de faire un truc compliqué. Mais plutôt d’avancer par petites itérations, les plus petites possibles ! Une quantité minimale de code pourrait être de dire que la fonction renvoie toujours 1. Ça va permettre de faire passer le test. Si j’envoie 0 et 1 pour a et b… la fonction va bien renvoyer 1 ✅
→ Je vais ensuite “refactorer” le code. C’est à dire le remettre en forme, le rendre plus lisible, plus facile à lire. Mais sans modifier son comportement. Ici il y a peu de choses à faire puisque le code est très très simple. Parfois on doit aller plus loin.
Prenons l’exemple d’un fichier Excel comme celui ci-dessous. Le code sans refacto serait un peu “brouillon”, artisanal. On fait la somme des cellules à la main. Et on a ajouté la constante en C2 directement. Le problème c’est que si je change C2 (c’est souvent l’idée), ça ne se répercutera pas. Mais en esprit TDD, ça n’est pas grave car c’était le code minimal pour faire passer le test. En revanche dans cette phase de refacto, on fait les choses un peu mieux et on rajoute la fonction SOMME et on met C2.

Pourquoi est-ce pertinent ?
Pour deux raisons qui sont très pertinentes pour les PMs malgré le caractère technique de cette activité :
→ La documentation sous forme de code est à jour tout le temps. C’est la conséquence du fait d’écrire le test en parallèle du code. À chaque instant, le logiciel construit, possède le comportement attendu. C’est à dire celui qui est validé par les tests. Pas possible d’éviter le contrôle des tests. Ma fonction qui doit additionner a et b, doit toujours bien les additionner, sinon je le verrai tout de suite. L’avantage à ça, en plus du niveau de vérification, c’est que j’ai juste à vérifier le test pour comprendre le fonctionnement de la fonction ou ce qu’on attend d’elle. Ces tests constituent la documentation à jour du comportement exact du logiciel. Il n’y a donc pas d’écart entre ce qui est développé et ce qui est documenté.
→ Le code est de meilleure qualité grâce à l’hygiène du refactoring continu et discipliné. Tous les cycles de développement TDD passent par du refactoring qui permet d'améliorer la structure interne du code sans modifier son comportement. Cela introduit une discipline d'amélioration de la structure du code en continu. Fait comme ça, petit à petit mais dans la durée, le refactoring est plus efficace et moins cher au global. C’est comme toutes les règles d'hygiène (coût très faible pour un.e chirurgien.ne de se laver les mains avant chaque opération ; coût très élevé d'une infection post-intervention chirurgicale)
J’avais écrit un article en anglais complet sur le TDD. Si ça vous intéresse, il est ici.
Intégration continue
Qu’est-ce que c’est ?
Lorsqu’on développe un logiciel, on écrit des lignes de code. Ces lignes de code permettent ensuite de créer le logiciel auquel l’utilisateur accède, soit en l’installant sur son ordinateur (comme Outlook) ou sur son portable (comme Instagram), soit en y accédant par l’intermédiaire de son navigateur (comme le site web amazon.com).
Pour des logiciels complexes, il est nécessaire d’avoir plusieurs développeurs qui écrivent des lignes de code en parallèle. Or, il peut arriver que deux développeurs travaillent en même temps sur les mêmes lignes de code. Ou en tout cas que le travail d’un développeur ait un impact sur les lignes de code en cours de modification par un autre développeur.
Un peu de la même manière que lorsque plusieurs personnes modifient en parallèle un document en simultané sur un drive, cela crée des problèmes, des “conflits de version”.
Et bien l’intégration c’est cette action de fusionner sa modification avec le document avant modification.
Reprenons l’exemple du drive :
→ J’ouvre un Google Doc sur mon drive
→ Je fais mes modifications en me déconnectant d’Internet
→ Je me reconnecte à Internet et je synchronise mes modifications
Il se passe la même chose avec le code, sauf que ce ne sont pas des modifications sur un Google Doc mais bien des lignes de code qui vont évoluer dans le fichier global qui stocke l’ensemble du code du produit.
Et quand on parle d’intégration “continue”, cela veut dire qu’on veut intégrer et fusionner les modifications le plus fréquemment possible.
On le voit sur le schéma ci-dessous : on veut fusionner / synchroniser les modifications le plus souvent possible dans le schéma du bas.
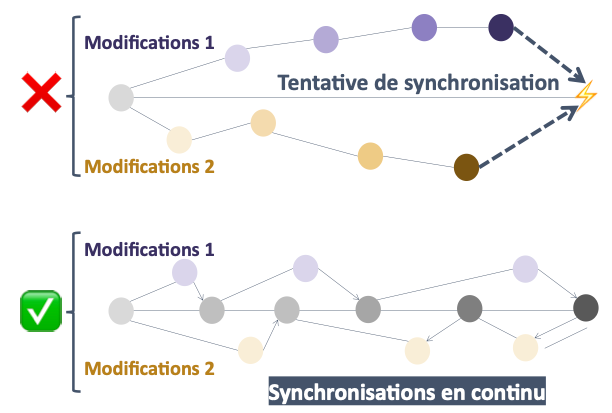
En quoi ça consiste ?
En pratique, l’intégration continue va se matérialiser par différentes activités :
→ Chaque développeur synchronise ses évolutions avec la version partagée du produit (le Google Doc sur le Drive) le plus souvent possible. L’objectif est donc de s’assurer qu’il y ait le moins d’écarts possibles (ou un écart minimal) entre le code qu’a écrit le développeur sur son PC et la version synchronisée et partagée avec tous les autres développeurs.
→ Bosser tous ensemble dès qu’un problème arrive. Pour que l’intégration continue fonctionne, les conflits de version ou problèmes post-modifs doivent être traités au plus vite. Prenons encore l’exemple du Google Doc. S’il y a eu des conflits de version… mais qu’on a continué à écrire par dessus, alors c’est encore plus dur de retrouver le problème initial et d’éviter qu’il y ait une escalade de problème avec d’autres conflits de version 😅
Pourquoi est-ce pertinent ?
Pour synchroniser le plus souvent possible les évolutions faites ! C’est toujours l’analogie avec le document sur Drive :
→ Moins de problématiques de fusions. C’est plus simple. Il n’y a pas de de conflits de version. Quand ça nous arrive sur les ppt ou des word, ça n’est pas agréable ni pratique. Mais sur du code, c’est vraiment l’enfer. Surtout lorsqu’il y a plusieurs conflits de version imbriqués les uns avec les autres. Parfois ça demande de faire plein d’archéologie pour tout remettre au propre.
→ Moins d’écarts entre les évolutions de chaque personne. On va tout de suite dans la même direction avec le bon niveau d’alignement. Imagine que tu rédiges un énorme paragraphe dans le Google Docs, et qu’un autre collègue rédige un autre en parallèle. Ça fait du travail en doublon pas pertinent. En étant synchronisé régulièrement, on a de la visibilité sur ce que chacun fait. Pas de risque de partir dans tous les sens.
→ Ça pousse à prendre de bonnes habitudes. Pousser régulièrement pour synchroniser et intégrer en continu ça peut paraître simple. Mais au delà d’une habitude pas forcément facile à prendre par chacun ; ça requiert aussi d’avoir une conception technique de haut niveau. Concrètement, il faut qu’on soit en mesure de déployer tout le temps notre code en production. C’est ce qui est fort avec l’intégration continue. C’est tous les bienfaits de la condition qu’il faut pour le faire. C’est comme le fait de faire un marathon. En tant que tel, il y a des bénéfices à courir un marathon. Mais je pense qu’une partie des bénéfices tient aussi à l’entraînement (plusieurs fois par semaine) et à l’hygiène de vie (nourriture saine, pas d’alcool) mis en place pour le faire dans de bonnes conditions.
Bref pour être des marathoniens du produit, il faut pratiquer l’intégration continue.
Conclusion
Merci de m’avoir suivi dans cette édition. J’espère que ça a été intéressant pour toi et que ça t’a appris des choses. On se retrouve la semaine prochaine 🙏
Si tu es trop impatient pour attendre, tu peux :
Me contacter pour échanger sur le sujet par mail ou par message LinkedIn 💪
Me retrouver sur Instagram
Partager la newsletter à des personnes susceptibles d'être intéressées 💪
Bon courage pour la semaine 😃
Victor
J'ai découvert le DDD lors d'une conférence de Guillaume de Saint Etienne à la School of Product de l'an dernier et j'ai vraiment aimé cette approche. Cela mérite d'être plus utilisé pour rapprocher les métiers des tech. Merci d'en avoir parlé